
The data for this project was taken from a Kaggle competition that involved predicting housing prices in Ames, Iowa. The data consists of 79 features for 1490 different houses.
Imputing missingness
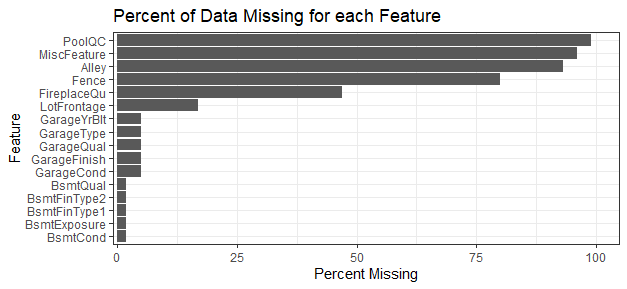
Data often consists of some level of missingness. Regression models do not handle missing data that well. The graph below shows the percent missingness of the features.

Different strategies were employed depending on the type of data needing imputation. Some categorical and ordinal data were imputed to “None” and zero respectively based on the feature not being present (ex: garage, pool, fence, etc.). Some special cases were imputed based on relationship to other categories. For instance, LotFrontage was imputed based on mean after grouping by Neighborhood and Lot Configuration. Some features were dropped based on not adding much value.
Feature engineering
Some features were created based on the values of other features, making for the ability to merge a few features together (ex: TotSF, PercBsmtFin, TotPorchSF, TotFullBath, TotalHalfBath). Categorical variables with low variable values but still may be important were also engineered (ex: Condition1 including near RRs, major roads, or positive places of interest).
EDA of the target variable


The raw data showed a right skew. Taking the log of the sale price shows a more normal distribution, which regression handles better.

Looking at a box plot of the house sale prices, there seem to be a couple outliers that I decided to drop from the data set.
Regressions
- Multiple Linear Regression
- Ridge Regression
- LASSO Regression
- ElasticNet Regression
- Random Forest
- Generalized Boosted Regression Modeling (GBM)
R-square and Kaggle scores
| Model | R-squared train | R-squared test | Score |
| MLR | 0.9211 | 0.8647 | 0.137 |
| Ridge | 0.9081 | 0.8622 | 0.1433 |
| LASSO | 0.89 | 0.8532 | 0.144 |
| ElasticNet | 0.9081 | 0.8622 | 0.1371 |
| Random Forest | 0.8857 | 0.8708 | 0.1376 |
| GBM | 0.9998 | 0.8647 | 0.1293 |
All Regression methods seem to be overfitting. The best model based on Kaggle score is Boosted Regression Tree model.
Feature importance

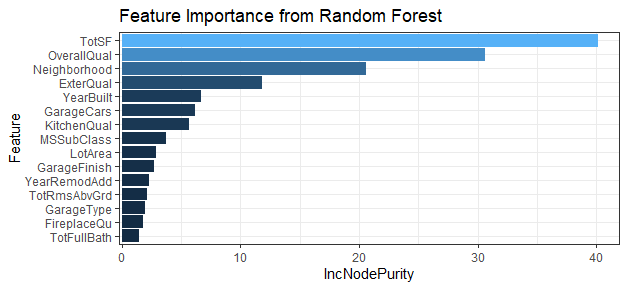
Different features were of more importance in different regression models. Although neighborhood seems to be of great importance when determining house prices.
Code available on GitHub.
Photo by Tierra Mallorca on Unsplash

