
")
")
In the rapidly evolving landscape of artificial intelligence, Retrieval-Augmented Generation (RAG) has emerged as a transformative approach that enhances the capabilities of large language models (LLMs).
By integrating real-time, external data sources into the response generation process, RAG addresses the limitations of traditional LLMs, such as outdated information and the generation of plausible yet incorrect responses, commonly referred to as “hallucinations.”
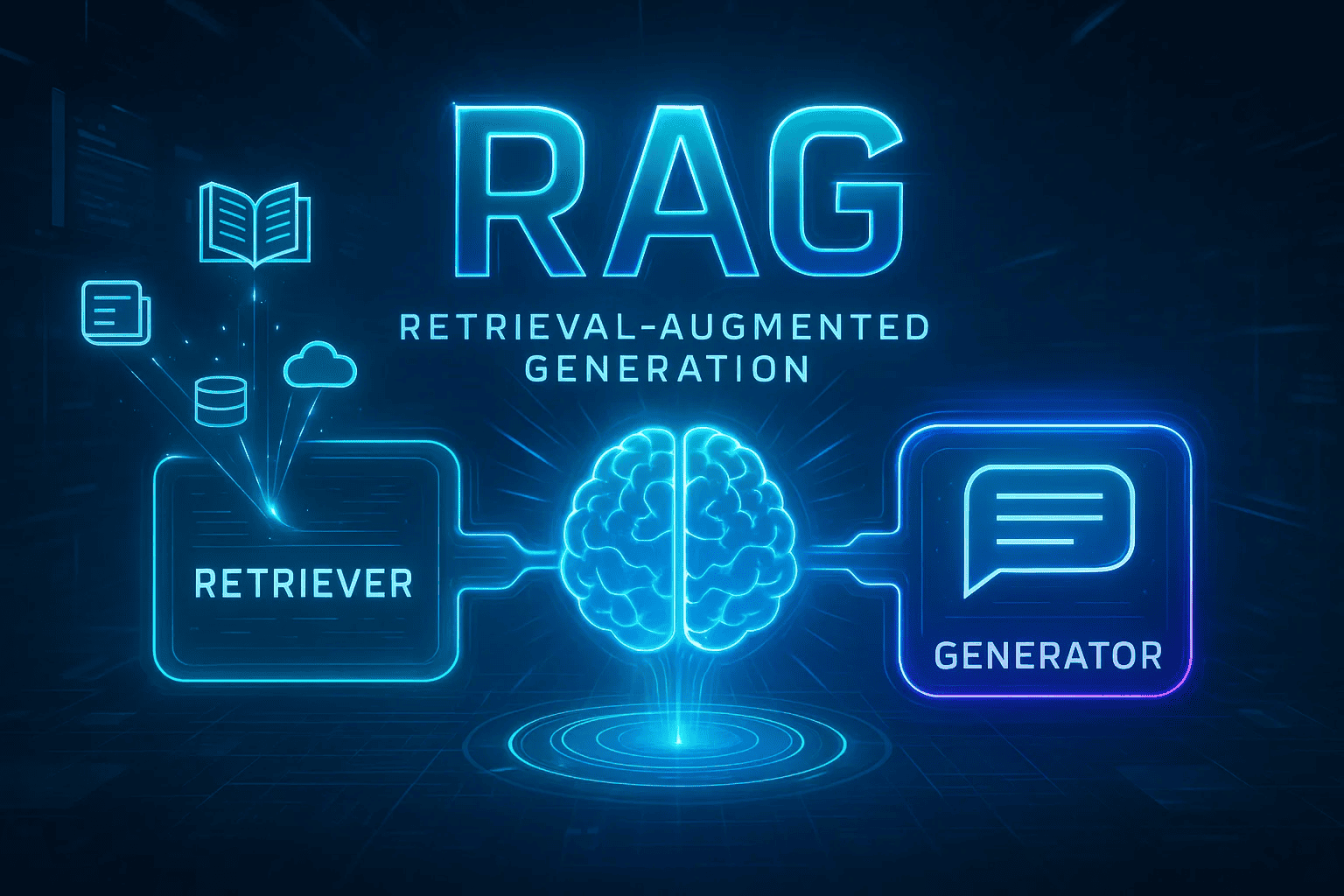
RAG operates by combining two core components:
- A retriever that searches for relevant information from external databases or documents,
- A generator that synthesizes this information with the user’s query to produce accurate and contextually appropriate responses.
This synergy allows AI systems to access up-to-date knowledge without the need for constant retraining, thereby improving efficiency and reliability.
In this comprehensive article, we will delve into the intricacies of RAG, exploring its architecture, benefits, challenges, and real-world applications. We will examine how RAG enhances the performance of LLMs, reduces hallucinations, and enables access to current information.
Additionally, we will discuss the practical steps involved in implementing RAG in various projects and industries, such as healthcare, finance, legal, and customer support.
By understanding the mechanisms and advantages of RAG, readers will gain insights into how this approach is revolutionizing the field of AI and paving the way for more accurate, reliable, and context-aware AI systems.
What is Retrieval-Augmented Generation (RAG)?
")
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is an advanced framework in artificial intelligence that enhances the capabilities of large language models (LLMs) by integrating external information sources into the response generation process.
Traditional LLMs generate responses based solely on the data they were trained on, which can lead to outdated or generic answers. RAG addresses this limitation by allowing models to retrieve and incorporate up-to-date, relevant information from external databases or documents, resulting in more accurate and contextually appropriate outputs.
The Evolution of RAG
The concept of RAG was introduced in 2020 by researchers at Meta AI (formerly Facebook AI Research). Their goal was to create a system that combines the strengths of information retrieval and text generation, enabling AI models to access and utilize external knowledge sources dynamically.
This approach allows models to provide responses that are not only coherent but also grounded in current and specific information, reducing the occurrence of inaccuracies or “hallucinations.”
")
Core Components of RAG
RAG operates through a synergistic interaction between two primary components:
- Retriever: This module searches external knowledge bases, such as databases or document repositories, to find information pertinent to the user’s query.
- Generator: Utilizing both the user’s original input and the retrieved information, this component crafts a comprehensive and contextually relevant response.
By combining these elements, RAG enables AI systems to produce responses that are informed by the most recent and relevant data available, thereby enhancing the reliability and usefulness of the information provided.
How Does Retrieval-Augmented Generation (RAG) Work?
 Work?")
Retrieval-Augmented Generation (RAG) enhances the capabilities of large language models (LLMs) by integrating external information retrieval into the response generation process. This approach allows AI systems to produce more accurate, up-to-date, and contextually relevant outputs.
Step 1: User Input
The process begins when a user submits a query or prompt to the AI system. This input can range from a simple question to a complex request for information.
Step 2: Retrieval Phase
Upon receiving the query, the system initiates a search for relevant information from external data sources. These sources can include databases, documents, or knowledge bases that contain pertinent information related to the query.
Step 3: Augmentation
The retrieved information is then combined with the original user query to create an augmented input. This enriched input provides the language model with additional context, enabling it to generate a more informed and accurate response.
Step 4: Generation Phase
The language model processes the augmented input to produce a coherent and contextually appropriate response. By leveraging both its pre-trained knowledge and the newly retrieved information, the model can deliver outputs that are both relevant and grounded in current data.
Step 5: Output Delivery
Finally, the system presents the generated response to the user. This output is tailored to the user’s original query, enriched by the integration of external information, and designed to provide accurate and reliable information.
By following this workflow, RAG systems effectively bridge the gap between static knowledge embedded in language models and dynamic, real-world information, resulting in AI outputs that are both trustworthy and contextually relevant.
Benefits of Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) offers several significant advantages that enhance the capabilities of large language models (LLMs) by integrating external information sources into the response generation process.
1. Enhanced Accuracy and Relevance
By accessing up-to-date external data, RAG enables LLMs to provide more accurate and contextually relevant responses. This integration reduces the likelihood of generating outdated or incorrect information, a common limitation of traditional LLMs.
2. Reduction of Hallucinations
RAG mitigates the issue of “hallucinations,” where models produce plausible-sounding but incorrect or nonsensical answers. By grounding responses in real-time data, RAG ensures that outputs are based on verifiable information, enhancing the trustworthiness of AI-generated content.
3. Access to Current Information
Traditional LLMs are limited to the data they were trained on, which can become outdated. RAG allows models to retrieve and incorporate the latest information from external sources, ensuring that responses reflect the most recent developments and data.
4. Cost-Effective Implementation
Implementing RAG is more cost-effective than retraining LLMs with new data. It allows for the integration of fresh information without the need for extensive computational resources, making it a practical solution for keeping AI systems up-to-date.
5. Improved Transparency and Trust
RAG can provide source attribution for the information used in generating responses. This transparency allows users to verify the origins of the information, fostering greater trust in AI-generated content.
6. Domain Adaptability
RAG enables LLMs to adapt to specific domains by retrieving relevant information from specialized databases or documents. This adaptability allows AI systems to provide more accurate and context-specific responses across various fields.
7. Scalability and Maintenance
RAG facilitates scalability by allowing AI systems to handle a wide range of queries using external data sources. Additionally, maintaining and updating the external knowledge base is more straightforward than retraining entire models, ensuring that the AI system remains current with minimal effort.
Challenges and Considerations in Implementing RAG
While Retrieval-Augmented Generation (RAG) offers significant advantages in enhancing the capabilities of large language models (LLMs), its implementation presents several challenges that organizations must address to ensure effective and reliable performance.
1. Retrieval Accuracy and Relevance
The effectiveness of a RAG system heavily depends on the accuracy and relevance of the retrieved documents. If the retrieval component fails to fetch pertinent information, the generated responses may be inaccurate or misleading. Factors such as ambiguous queries, inadequate indexing, or suboptimal search algorithms can contribute to retrieval inefficiencies.
2. Data Quality and Consistency
The quality of the external data sources used in RAG systems is paramount. Inconsistent formatting, outdated information, or the presence of redundant and irrelevant data can negatively impact the system’s performance. Ensuring that the knowledge base is regularly updated and curated is essential for maintaining the reliability of the generated outputs.
3. Integration Complexity
Integrating the retrieval and generation components of a RAG system can be complex. Ensuring seamless communication between these components requires careful design and implementation. Misalignment in data formats, tokenization discrepancies, or latency issues can hinder the system’s overall efficiency and effectiveness.
4. Computational Resources and Scalability
RAG systems can be resource-intensive, especially when dealing with large-scale data retrieval and processing. Organizations must ensure that their infrastructure can handle the computational demands of real-time data retrieval and response generation. Scalability considerations are crucial to accommodate growing data volumes and user demands.
5. Privacy and Security Concerns
Accessing and processing external data sources can raise privacy and security issues. Ensuring that sensitive information is protected and that data usage complies with relevant regulations is critical. Implementing robust access controls, encryption, and data anonymization techniques can help mitigate these concerns.
6. Evaluation and Monitoring
Assessing the performance of a RAG system involves evaluating both the retrieval and generation components. Developing comprehensive evaluation metrics and monitoring tools is essential for identifying areas of improvement and ensuring the system meets the desired accuracy and reliability standards.
7. User Trust and Transparency
Building user trust in AI-generated responses requires transparency in how the information is sourced and presented. Providing clear citations or references to the original data sources can enhance credibility. Additionally, designing user interfaces that allow users to explore the underlying data can foster greater trust and acceptance of the system’s outputs.
Addressing these challenges is crucial for the successful implementation of Retrieval-Augmented Generation systems. By proactively identifying and mitigating potential issues, organizations can leverage RAG to enhance the capabilities of their AI applications effectively.
Real-World Applications of Retrieval-Augmented Generation (RAG)
")
Retrieval-Augmented Generation (RAG) has transitioned from a theoretical concept to a practical solution across various industries. By integrating external data retrieval with language models, RAG enhances the accuracy and relevance of AI-generated responses.
Here are some real-world applications where RAG is making a significant impact:
1. Customer Support
RAG-powered chatbots and virtual assistants are revolutionizing customer service by providing accurate, context-aware responses. By accessing up-to-date product information and customer history, these systems can resolve inquiries efficiently, reducing the need for human intervention and improving customer satisfaction.
2. Healthcare
In the medical field, RAG assists healthcare professionals by retrieving the latest research, clinical guidelines, and patient data. This integration supports informed decision-making, enhances diagnostic accuracy, and ensures that patient care is based on the most current information available.
3. Finance
Financial institutions leverage RAG to analyze market trends, retrieve real-time financial data, and generate comprehensive reports. This capability enables more informed investment decisions, risk assessments, and strategic planning, keeping pace with the rapidly changing financial landscape.
4. Legal Industry
Law firms and legal departments utilize RAG to streamline legal research by retrieving relevant case laws, statutes, and legal documents. This application reduces the time spent on manual research, enhances the accuracy of legal arguments, and supports the drafting of well-informed legal documents.
5. Education and Training
Educational platforms incorporate RAG to provide personalized learning experiences. By retrieving relevant study materials and resources, RAG supports adaptive learning, helping students grasp complex concepts and stay updated with the latest academic developments.
6. E-commerce
E-commerce businesses employ RAG to enhance product recommendations and customer interactions. By retrieving information on customer preferences, browsing history, and product details, RAG enables personalized shopping experiences, increasing customer engagement and sales.
7. Human Resources
In HR, RAG aids in talent acquisition and employee training by retrieving candidate information, job descriptions, and training materials. This application streamlines recruitment processes and supports the development of effective training programs.
Implementing Retrieval-Augmented Generation (RAG) in Your Projects
Integrating Retrieval-Augmented Generation (RAG) into your projects can significantly enhance the capabilities of large language models (LLMs) by providing them with access to up-to-date and contextually relevant information. This integration allows for more accurate, reliable, and domain-specific responses. Here’s a comprehensive guide to implementing RAG effectively:
1. Define Clear Objectives
Begin by identifying the specific goals you aim to achieve with RAG. Whether it’s improving customer support, enhancing content generation, or providing real-time data analysis, having a clear objective will guide the design and implementation of your RAG system.
2. Prepare and Structure Your Data
The quality of your RAG system heavily depends on the data it accesses. Ensure that your data sources are reliable, up-to-date, and relevant to your domain. Organize the data in a structured format, and consider preprocessing steps such as cleaning, normalization, and chunking to facilitate efficient retrieval.
3. Choose Appropriate Tools and Frameworks
Several tools and frameworks can assist in building RAG systems:
- LangChain: A framework designed for developing applications with LLMs, offering components for retrieval and generation.
- LlamaIndex: Provides a simple interface to connect LLMs with external data sources, facilitating the creation of RAG pipelines.
- Haystack: An open-source framework that supports building search systems and RAG applications with modular components.
Select the tools that best align with your project’s requirements and your team’s expertise.
4. Implement the Retrieval Component
Develop the retrieval mechanism to fetch relevant documents or data segments based on user queries. This typically involves:
- Embedding Generation: Convert documents into vector representations using embedding models.
- Vector Storage: Store these embeddings in a vector database, such as Pinecone or FAISS, to enable efficient similarity searches.
- Query Processing: Transform user queries into embeddings and retrieve the most relevant documents from the vector database.
5. Integrate the Generation Component
Once relevant documents are retrieved, integrate them with the user’s query to form an augmented input. Feed this input into the LLM to generate a response that is both contextually relevant and grounded in the retrieved data.
6. Evaluate and Iterate
Continuously assess the performance of your RAG system through metrics such as accuracy, relevance, and response time. Gather user feedback to identify areas for improvement, and iterate on your system’s design and implementation accordingly.
7. Address Ethical and Privacy Considerations
Ensure that your RAG system complies with data privacy regulations and ethical standards. Implement measures to protect sensitive information and prevent the dissemination of biased or inappropriate content.
Conclusion and Future Outlook of Retrieval-Augmented Generation (RAG)
")
Retrieval-Augmented Generation (RAG) has emerged as a transformative approach in the realm of artificial intelligence, addressing the limitations of traditional large language models (LLMs) by integrating external information retrieval mechanisms.
By combining the generative capabilities of LLMs with real-time data access, RAG enhances the accuracy, relevance, and contextuality of AI-generated responses.
The Road Ahead
As we look to the future, several key trends and developments are poised to shape the evolution of RAG:
- Multimodal Integration: Future RAG systems are expected to incorporate various data modalities, including text, images, audio, and video, enabling more comprehensive and nuanced AI interactions.
- Enhanced Personalization: Advancements in user profiling and context-aware retrieval will allow RAG systems to deliver highly personalized responses, catering to individual user needs and preferences.
- Real-Time Data Processing: The integration of streaming data sources will empower RAG models to provide up-to-the-minute information, crucial for applications in finance, news, and emergency response.
- Improved Interpretability: Efforts to make RAG systems more transparent will focus on elucidating how retrieved information influences generated outputs, fostering greater trust and accountability.
- Scalability and Efficiency: Optimizing the computational efficiency of RAG architectures will be essential to support large-scale deployments across various industries and applications.
In conclusion, RAG stands at the forefront of AI innovation, offering a robust framework for generating accurate, context-rich, and up-to-date information.
Its continued development and integration into diverse applications promise to redefine the capabilities of AI systems, making them more reliable and aligned with human needs.
Frequently Asked Questions (FAQ) on Retrieval-Augmented Generation (RAG)
1. What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is an AI framework that enhances the capabilities of large language models (LLMs) by integrating external information retrieval into the response generation process. This approach allows LLMs to access up-to-date and contextually relevant information from external sources, resulting in more accurate and reliable outputs.
2. How does RAG differ from traditional language models?
Traditional LLMs generate responses based solely on their training data, which can become outdated over time. RAG, on the other hand, retrieves current information from external databases or documents at the time of query, ensuring that responses are grounded in the most recent and relevant data.
3. What are the main components of a RAG system?
A typical RAG system comprises two primary components:
- Retriever: Fetches relevant documents or data segments from external sources based on the user’s query.
- Generator: Processes the retrieved information along with the original query to generate a coherent and contextually appropriate response.
4. What are the benefits of using RAG?
Implementing RAG offers several advantages:
- Enhanced Accuracy: By accessing real-time data, RAG reduces the likelihood of outdated or incorrect responses.
- Reduced Hallucinations: Grounding responses in external data minimizes the generation of plausible but incorrect information.
- Cost-Effective Updates: RAG allows models to stay current without the need for frequent retraining.
- Domain Adaptability: Easily integrates with specific domains by retrieving relevant information from specialized databases.
5. In which industries is RAG commonly applied?
RAG has versatile applications across various sectors, including:
- Healthcare: Assisting in clinical decision-making by retrieving the latest medical research.
- Finance: Providing real-time market analysis and financial reporting.
- Legal: Streamlining legal research by accessing relevant case laws and statutes.
- Customer Support: Enhancing chatbot responses with up-to-date product information.
- Education: Offering personalized learning experiences by retrieving relevant study materials.
6. What challenges are associated with implementing RAG?
While RAG offers significant benefits, it also presents certain challenges:
- Retrieval Accuracy: Ensuring the retriever fetches the most relevant and high-quality information.
- Integration Complexity: Seamless communication between retrieval and generation components requires careful design.
- Data Privacy: Accessing external data sources necessitates robust privacy and security measures.
- Computational Resources: Handling large-scale data retrieval and processing can be resource-intensive.
7. How does RAG handle outdated or conflicting information?
RAG systems rely on the quality and recency of their external data sources. Implementing regular updates and curating the knowledge base can mitigate the risks of outdated or conflicting information. Additionally, incorporating mechanisms to assess the credibility of sources can enhance the reliability of responses.
8. Can RAG be integrated with existing AI systems?
Yes, RAG can be integrated into existing AI infrastructures. Frameworks like LangChain, LlamaIndex, and Haystack facilitate the development and integration of RAG systems, allowing organizations to enhance their AI applications with retrieval capabilities.
🌟 Follow Us
💬 I hope you like this post! If you have any questions or want me to write an article on a specific topic, feel free to comment below.

