


Remember when search meant tokenizing text and hoping for keyword hits? In 2025, that feels prehistoric. Large-language models, recommendation engines, and multimodal apps all speak the language of vectors—dense arrays that capture meaning far better than rows and columns ever could.
As demand for retrieval-augmented generation (RAG) and semantic search skyrockets, a brand-new layer of infrastructure has emerged: vector databases.

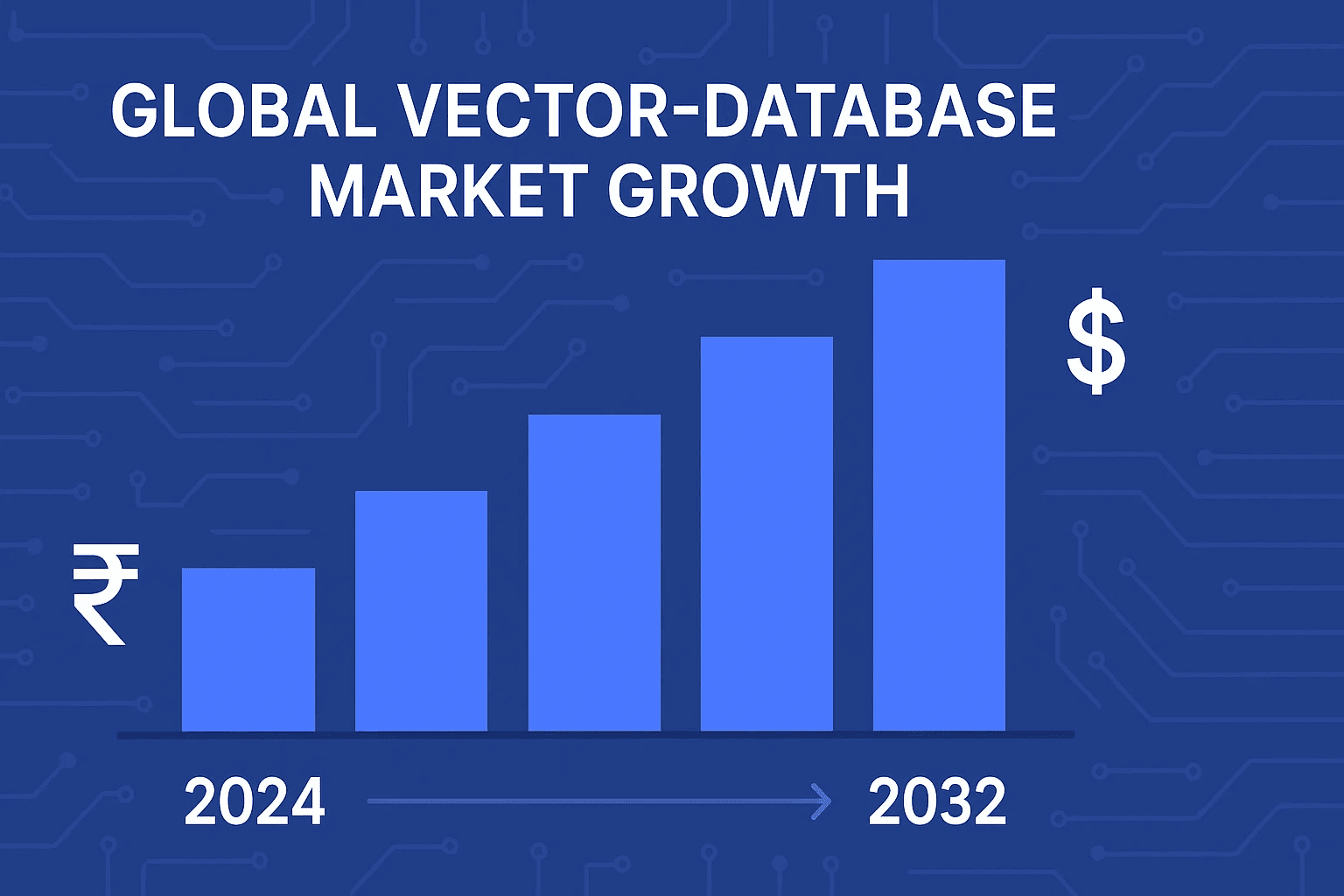
The surge is real. Market analysts peg the vector-database space at roughly ₹18,000 crore ($2.2 B) in 2024 and project it to rocket toward ₹90,000 crore ($10.6 B) by 2032—an annual growth clip above 21 percent.
Venture cash is pouring in (Pinecone alone has raised over $130 million), and open-source downloads are exploding (Weaviate now exceeds one million pulls per month).
Why Vector Databases Are Exploding in 2025
If you’re building anything AI-native this year, choosing the right vector store is no longer optional it’s table stakes.
Let’s first unpack why these databases exploded so quickly.
1️⃣ Why Vector Databases Are Exploding in 2025
The GenAI domino effect
ChatGPT’s success proved that adding private context beats fine-tuning for most real-world tasks. Enterprises reacted by piping internal documents into RAG pipelines, which in turn requires a store built for billion-row similarity look-ups. Vector databases deliver that at millisecond latency.

Moore’s Law for embeddings
New models like text-embedding-3-large turn a single PDF page into hundreds of 1,536-dimensional vectors. Multiply that by millions of documents and you quickly outgrow what Elasticsearch k-NN or a DIY FAISS index can handle on one node.
Dedicated vector engines bring HNSW graphs, IVF-PQ compression, and effortless sharding to the party no extra plumbing needed.
Money talks
Investors love infrastructure that every AI workflow must touch. Big funding rounds are fueling aggressive roadmaps think serverless tiers, multi-tenant isolation, hybrid scalar-plus-vector queries, and SOC-2 compliance baked in.
That capital also buys developer evangelism and conference buzz, pushing adoption faster.
OSS + cloud convenience
Projects like Milvus and Chroma let you start locally with Docker, then lift-and-shift to managed services when traffic spikes. This “open core” path mirrors Kubernetes’ rise and lowers switching costs for teams still experimenting.
Pro Tip 🛠️If you’re still in proof-of-concept mode, pair a lightweight library (Chroma or pgvector) with an SSD laptop to validate recall and latency. Only graduate to a fully managed cluster once you hit roughly ten million vectors or need multi-region high availability.
2️⃣ What Makes a Vector Database “Popular”?

Popularity isn’t just about headline funding rounds or flashy conference booths. For practitioners, a vector database earns its stripes through a blend of technical performance, developer experience, and ecosystem momentum.
Here are the metrics that matter in 2025:
| Criterion | Why It Matters | What “Good” Looks Like |
|---|---|---|
| Query Latency & Recall | Millisecond response and > 95 % recall keep RAG chatbots feeling instant and accurate. | p95 < 30 ms on one-million-vector HNSW index, recall ≥ 0.95. |
| Scalability | Horizontal sharding without manual partition pain lets you grow from 10 M to 10 B vectors. | Auto-rebalancing clusters; linear throughput scaling. |
| Hybrid Search | Real apps filter on metadata and vector similarity. | Boolean/time filters combined with ANN in a single query. |
| Ecosystem / SDKs | Multiple language clients, LangChain/LLamaIndex plug-ins, and notebook samples cut integration time. | Official Python, JavaScript, Go SDKs plus open-source connectors. |
| Cloud & Edge Options | Teams want both local dev and one-click production hosting. | Docker image, Helm chart, and managed SaaS with usage-based pricing. |
| Community & Support | Active Slack/Discord, weekly releases, and docs signal project health. | > 5 k GitHub stars, monthly patch cadence, live office hours. |
| Cost Transparency | Predictable pricing beats surprise egress or ingest fees. | Simple “per-million-vector-hours” or node-hour models. |
2025 Popularity Snapshot
- GitHub Stars (April 2025): Milvus ~25 k, Qdrant ~9 k, Weaviate ~8 k, Chroma ~6 k, pgvector ~4 k.
- Monthly Docker Pulls: Weaviate > 1 M, Milvus ~700 k, Pinecone’s local server ~400 k.
- Google Trends: Searches for “vector database” grew 11× between Jan 2023 and Jan 2025.
Real-World Check 🔍A fintech startup choosing a store for fraud-signal embeddings benchmarked latency on a 3-node cluster (1 M, 10 M, 100 M vectors). They eliminated any option exceeding 40 ms at the 10 M mark, instantly narrowing the field to four contenders.
By evaluating your shortlist against these seven criteria, you’ll distinguish hype from genuinely production-ready platforms and set the stage for our deep dive into which engines stand out.
3️⃣ Quick Feature Matrix – 2025 Leaders at a Glance
Below is a one-screen comparison of the six vector engines dominating mindshare this year.

| Vector DB | License / Hosting | Core ANN Algo* | Hybrid Search (metadata + vector) | Multi-Tenant | Deployment Options | Pricing Model |
|---|---|---|---|---|---|---|
| Pinecone | Proprietary SaaS | HNSW | Yes (metadata filters) | Yes (namespaces) | Fully managed, serverless | Usage-based (per-vector-hour + ops) |
| Weaviate | Apache 2.0 (OSS) / SaaS | HNSW | Yes (vector + filters + BM25) | Yes | Docker, Kubernetes, Weaviate Cloud | Free OSS; SaaS per-node-hour |
| Chroma | MIT (OSS) / Serverless Beta | HNSW | Partial (vector + doc IDs) | No (single-tenant) | Local lib, Docker, Chroma Cloud Beta | Free local; cloud pay-as-you-go |
| Milvus | Apache 2.0 (OSS) / Zilliz Cloud | IVF-PQ, HNSW, ANNOY | Yes | Yes | Docker, K8s, Zilliz Cloud | Free OSS; cloud node-hour |
| Qdrant | Apache 2.0 (OSS) / Cloud | HNSW | Yes (payload filters) | Yes (collections) | Docker, K8s, Qdrant Cloud | Free OSS; cloud storage + compute |
| pgvector (PostgreSQL ext.) | PostgreSQL License | HNSW, IVF-Flat | Yes (SQL WHERE + <->) | Inherits PG roles | Self-hosted, any Postgres cloud | Standard Postgres pricing |
Core ANN Algo – primary approximate-nearest-neighbor index used today; many engines also support brute-force or additional methods.
How to read this table
- License / Hosting: OSS flexibility vs. fully managed convenience.
- Hybrid Search: Crucial if you need both semantic relevance and classical filters (price, tags, dates).
- Multi-Tenant: Required for SaaS scenarios or isolating team workspaces.
- Deployment Options: Indicates how frictionless it is to move from laptop to prod cluster.
- Pricing Model: Helps budget for scale (vector-hour makes costs predictable; node-hour favors steady workloads).
With the landscape mapped, let’s zoom into each database to understand strengths, weaknesses, and real-world fit.
4️⃣ The Big Six – Most Popular Vector Databases
Below you’ll find a repeatable “snapshot” for each engine:

4.1 Pinecone
At-a-Glance Managed, serverless, and built exclusively for vectors no servers to size, just collections and queries.
Key Features
HNSW index with automatic replicas
Namespaces for multi-tenant isolation
Built-in metadata filters + sparse & dense hybrid search
SOC 2 Type II and HIPAA compliance
Ideal Use Cases Enterprise-grade RAG chatbots, personalization at global scale, teams that never want to touch ops.
Link: https://www.pinecone.io/
Code Walkthrough (Python)
import pinecone, os
pinecone.init(api_key=os.getenv("PINECONE_KEY"), environment="gcp-starter")
index = pinecone.Index("products")
index.upsert([( "id1", vec1, {"brand": "ACME"} )])
query = index.query(vec_query, top_k=3, filter={"brand": "ACME"})
Pricing / Licensing Usage-based: you pay per-vector-hour plus read/write ops; free tier up to 5 K vectors.
Real-World ExampleA Fortune 500 retailer pipes daily product embeddings into Pinecone to power semantic search across 20 million SKUs—with zero downtime during Black Friday traffic spikes.
4.2 Weaviate
At-a-Glance Open-source core plus SaaS option; GraphQL-style API and flexible hybrid search.
Key Features
HNSW indexes, optional BM25 text ranking
Automatic schema inference (add vector + metadata in one JSON)
Module system: built-in OpenAI, Cohere, PaLM vectorizers
Multi-tenant via separate classes on Weaviate Cloud
Ideal Use Cases Teams wanting OSS freedom, rapid prototyping, or complex filters (geo-location, range queries).
Link: https://weaviate.io/
Code Walkthrough (Python)
import weaviate, os
client = weaviate.Client(url="http://localhost:8080")
client.schema.create_class({
"class": "Article",
"vectorizer": "none",
"properties": [
{"name": "text", "dataType": ["text"]}
]
})
client.batch.add_data_object({"text": "Vector DBs rock!"}, "Article")
near_vec = {"vector": vec_query}
result = client.query.get("Article", ["text"]).with_near_vector(near_vec).with_limit(3).do()
Pricing / LicensingApache-2 OSS (free); SaaS billed per node-hour with autoscaling.
Real-World ExampleAn EdTech startup stores 15 million Q&A embeddings and runs hybrid queries (difficulty, tags + vector) to serve personalized practice tests.
4.3 Chroma
At-a-GlanceLightweight Python library with a “batteries-included” feel; ideal for notebooks and local dev.
Key Features
Simple
pip install chromadb→ start in secondsHNSW under the hood, auto-persists to disk
No server required (but server mode exists)
Serverless cloud beta for instant scaling
Ideal Use Cases Hackathons, proof-of-concept RAG apps, desktop tools needing vector recall offline.
Link: https://www.trychroma.com/
Code Walkthrough (Python)
import chromadb
client = chromadb.Client()
collection = client.create_collection("notes")
collection.add(ids=["n1"], embeddings=[vec1], documents=["AI note 1"])
hits = collection.query(query_embeddings=[vec_query], n_results=3)
Pricing / LicensingMIT license (fully free); cloud tier pricing TBD but promises pay-as-you-go.
Real-World ExampleA solo developer ships an offline research assistant that bundles Chroma with a local LLM—no internet required.
4.4 Milvus
At-a-GlanceHigh-throughput, distributed engine born at scale; commercial cloud via Zilliz.
Key Features
Multiple ANN algorithms (IVF-PQ, HNSW, DiskANN)
GPU acceleration for billion-vector indexing
Elastic horizontal scaling with etcd + Pulsar
SQL-like milvus-lite for lightweight deployments
Ideal Use Cases Massive multimedia archives, ad-tech click-stream embeddings, projects needing GPU speed.
Link: https://milvus.io/
Code Walkthrough (Python)
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection
connections.connect("default", uri="tcp://localhost:19530")
schema = CollectionSchema([
FieldSchema("id", DataType.INT64, is_primary=True, auto_id=False),
FieldSchema("vec", DataType.FLOAT_VECTOR, dim=768)
])
coll = Collection("images", schema)
coll.insert([[1], [vec1]])
coll.load()
hits = coll.search([vec_query], "vec", param={"metric_type": "L2"}, limit=5)
Pricing / LicensingApache-2 OSS; Zilliz Cloud charges per node-hour with volume discounts.
Real-World ExampleA video-hosting platform indexes frame embeddings (2 B vectors) on GPU-backed Milvus and streams similarity search at < 50 ms.
4.5 Qdrant
At-a-GlanceRust-based engine emphasizing payload filters and speed; single-binary deploy.
Key Features
HNSW index with quantization options
Rich structured payloads, nested JSON filters
REST and gRPC APIs; flatbuffers for low overhead
WAL + snapshots for crash safety
Ideal Use Cases IoT telemetry anomaly detection, e-commerce catalogs needing complex attribute filters, Rust or Go microservices.
Link: https://qdrant.tech/
Code Walkthrough (Python)
import qdrant_client
client = qdrant_client.QdrantClient(":6333")
client.recreate_collection("products", vector_size=512, distance="Cosine")
client.upsert(
collection_name="products",
points=[
qdrant_client.PointStruct(
id=1,
vector=vec1,
payload={"brand": "ACME"}
)
]
)
hits = client.search(
collection_name="products",
query_vector=vec_query,
limit=5,
query_filter={
"must": [
{"key": "brand", "match": {"value": "ACME"}}
]
}
)
Pricing / Licensing Apache-2 OSS; Qdrant Cloud bills by storage + compute hour.
Real-World Example A travel site logs user session vectors and runs real-time anomaly detection to flag bot activity all within one lightweight Qdrant cluster.
4.6 pgvector (PostgreSQL Extension)
At-a-GlanceBring vectors to the database you already know; perfect for teams committed to SQL.
Key Features
Adds
vectorcolumn type and<->operator for L2/cosine/inner-product similaritySupports HNSW and IVF-Flat indexes (Postgres 15+)
Works with joins, transactions, and every Postgres feature
Cloud support via Supabase, Neon, AWS RDS (extension install)
Ideal Use Cases Integrating semantic search into existing OLTP apps, BI dashboards combining vectors + relational data.
Link: https://github.com/pgvector/pgvector
Code Walkthrough (SQL + Python)
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE docs(id bigserial PRIMARY KEY, embedding vector(1536), content text);
CREATE INDEX ON docs USING hnsw (embedding vector_l2_ops);
cur.execute("SELECT content FROM docs ORDER BY embedding <-> %s LIMIT 5", (vec_query.tolist(),))
Pricing / LicensingOpen-source under PostgreSQL license; pay your usual Postgres hosting costs.
Real-World ExampleA SaaS CRM adds “find similar leads” by simply adding a vector column no separate infra or language changes required.
5️⃣ Decision Framework – Choosing the Right Vector Database

Not every project needs Pinecone’s multi-region muscle or Milvus’s GPU horsepower. Use the six-question flow below to shave hours off evaluation time.
⚡ Rapid-Fire Flowchart
Self-hosted or Fully Managed?
Need zero ops? → Pinecone or Weaviate Cloud.
Comfortable with Helm charts? → Milvus, Qdrant, or Weaviate OSS.
Already running Postgres? → pgvector wins on simplicity.
How Many Vectors—Today and in 12 Months?
< 10 M and likely steady → Chroma or pgvector stay lean.
> 10 M and growing fast → Milvus, Pinecone, Weaviate, Qdrant.
Do You Need Hybrid Filters (price, tag, date)?
Yes → Shortlist Weaviate, Qdrant, pgvector.
No → Any engine works; prioritize latency and cost.
Latency SLA?
Real-time UX < 50 ms → Look for HNSW + RAM-heavy configs (Pinecone, Milvus, Qdrant).
Async / batch analytics → IVFPQ or DiskANN variants save money (Milvus, pgvector).
Compliance & Security Requirements?
SOC 2 / HIPAA → Pinecone, Weaviate Cloud (enterprise tier).
On-prem only → Milvus OSS or Qdrant OSS.
Language & Framework Preference?
Pure SQL stack → pgvector.
Python notebooks & LangChain → Chroma, Weaviate, Pinecone.
Rust / Go micro-services → Qdrant (gRPC + Rust core).
Real-World Example 💡An e-commerce marketplace needed product-search RAG with 15 M SKUs, strict price filters, and Black-Friday-proof latency. They benchmarked Weaviate Cloud vs. Pinecone. Pinecone delivered lower p95 latency (23 ms vs. 34 ms) but Weaviate’s hybrid filtering and OSS fallback tipped the decision—plus a 22 % lower monthly bill at steady traffic.
Quick Tips Before You Commit
| Tip | Why It Saves Pain |
|---|---|
| Load sample traffic first | Run 24-hour soak tests; watch index-rebuild impact. |
| Measure recall, not just speed | Aggressive compression can drop accuracy below acceptable thresholds. |
| Plan re-index strategy | Some engines rebuild offline; others handle live inserts seamlessly. |
| Budget egress costs | Managed clouds may charge per-GB when vectors leave their network. |
Pick the first database that clears all six questions, spin up a proof-of-concept, and profile with your real embeddings not dummy vectors.
6️⃣ Best Practices for Running Vector Databases in Production

Deploying a vector store is easy; keeping it fast, accurate, and cost-efficient at 3 a.m. is where the craft lies. Use the checklist below to avoid the gotchas that trip up most first-time teams.
6.1 Index-Building & Refresh Strategy
Batch your inserts: Aim for 500 – 5,000 vectors per batch to minimize write-amplification.
Stagger rebuilds: For engines that require periodic index compaction (e.g., IVF-PQ), run during low-traffic windows.
Warm the cache: After a fresh node joins, pre-query the top-N most common embeddings to prime RAM and avoid cold-start latency.
6.2 Hybrid Filtering & Metadata Modeling
| Do | Don’t |
|---|---|
| Store scalar metadata in separate, indexed columns/fields. | Jam large blobs or JSON arrays into the payload—filters will crawl. |
| Keep filter cardinality reasonable (e.g., < 10 k unique values). | Use high-cardinality fields (user-ID) as primary filters—index bloat. |
| Normalize dates and numerical ranges to ints for faster ops. | Rely on string parsing at query time. |
6.3 Security & Compliance
Encrypt at rest and in transit. Enable TLS for client connections and cluster gossip.
Isolate tenants. Use namespaces (Pinecone) or collections (Qdrant) rather than sharing one massive index.
Hash or truncate embeddings that might leak PII. Remember: vectors derived from text can still contain sensitive information in latent form.
6.4 Monitoring & Alerting Essentials
| Metric | Why You Care | Typical Threshold |
|---|---|---|
| p95 Latency | User-facing speed; spikes signal hot shards. | Keep < 50 ms. |
| Recall (offline test) | Silent accuracy drift kills search quality. | Re-index if recall < 0.92. |
| Index Size Growth | Unexpected jumps hint at duplicate vectors. | Alert if daily growth > 5 %. |
| Memory Usage / Cache Hit Rate | HNSW lives in RAM; low hit rate hurts. | Maintain > 60 % cache hits. |
Tip: Expose Prometheus metrics (
/metrics) or use built-in cloud dashboards, then set Grafana alerts for p95 > 2× baseline.
6.5 Backup, DR & Upgrades
Snapshots every 15 min to object storage; retain daily full backups for 30 days.
Rolling upgrades—add a new version node, rebalance shards, then drain the old one to avoid index rebuild downtime.
Validate index-format compatibility before minor-version jumps (e.g., Milvus 2.2 → 2.3).
6.6 Cost Optimisation Playbook
Tiered storage. Pin “hot” indices on NVMe; offload long-tail vectors to cheaper block storage.
Auto-scale reads, not writes. Most workloads are read-heavy; write nodes can stay modest.
Prune stale vectors. Delete embeddings for inactive users/products to curb storage creep.
Choose the right metric. Cosine distance can be 20 – 30 % cheaper than dot-product when using HNSW due to simpler normalisation.
Lock these best practices in early and your vector layer will stay invisibly reliable—letting your team focus on building features instead of fighting fires.
7️⃣ Future Trends Beyond 2025

7.1 Multimodal Vector Stores
Text embeddings were just the opening act. Next-gen engines are adding native support for image, audio, and even sensor-data vectors in a single index. Expect unified queries like “find tweets that sound like this podcast clip and mention these keywords.”
7.2 Serverless Cold-Tier Storage
Most vectors are “write once, read rarely.” Vendors are rolling out S3-style cold tiers that hydrate to RAM only on demand, slashing costs by 60–80 %. Think of it as Glacier for embeddings.
7.3 Local LLM Co-Processors
Instead of shipping vectors out to an external model, some databases will embed transformer runners right next to the index—allowing embeddings, re-ranking, or even generation to happen in situ with microsecond data access.
7.4 Auto-Sharding & Global Consistency
Cross-region replication is getting smarter: upcoming releases promise automatic shard rebalancing based on query heatmaps and vector density, plus eventual-consistency models tuned for ANN graphs.
7.5 Fully Homomorphic Encryption (FHE) Trials
Privacy tech isn’t just for buzzwords anymore. Early research prototypes show cosine-similarity search over encrypted vectors with single-digit-millisecond overhead—opening the door to zero-trust SaaS deployments.
7.6 Vector-Native SQL Standards
Working groups are drafting extensions to ANSI SQL for ORDER BY VECTOR_SIM(...) and CREATE VECTOR INDEX. Once standardised, expect Postgres, MySQL, and cloud data warehouses to bake in vector ops as first-class citizens.
Watch List
Pinecone’s forthcoming Edge Runtime (vectors at CDN POPs)
Milvus 3.0 roadmap: DiskANN + serverless ingest
Qdrant “Project Nebula”: sharded HNSW with graph-aware load balancing
Weaviate’s multi-modal module merging image + text embeddings in one API call
The takeaway: the line between database and AI engine is blurring fast. Keeping an eye on these trends now will future-proof your architecture for the next big jump in model capabilities.
8️⃣ Summary & Next Steps
Vector databases have sprinted from niche research tools to “must-have” infrastructure in just two years. You’ve now seen why they exploded, how to judge popularity, the strengths of the Big Six, a practical decision framework, production-grade best practices, and the trends that will reshape the space after 2025.
Key takeaways
Match the engine to the workload: Pinecone for turnkey scale, Weaviate for OSS flexibility, Milvus for GPU speed, Qdrant for complex filters, Chroma for fast prototyping, pgvector for SQL simplicity.
Plan for growth on day 1: Index-refresh cadence, hybrid filtering, and auto-scaling policies save painful retrofits later.
Monitor what matters: p95 latency, recall, and index-size drift are the early-warning lights for vector stores.
Stay future-proof: Multimodal vectors, serverless cold tiers, and vector-native SQL will reach production sooner than you think.
What to do now
Grab the sample notebook (link below) to spin up each database locally and run a side-by-side latency/recall test with your own embeddings.
Subscribe to our youtube for monthly deep dives on RAG architectures and vector-search benchmarks.
Share this post with your engineering team because picking the wrong store today means a migration tomorrow.
9️⃣ Frequently Asked Questions
1. What exactly is a vector database?
A vector database stores high-dimensional embeddings and provides fast approximate-nearest-neighbor (ANN) search, letting you find “similar” items by meaning rather than keywords.
2. How is it different from Elasticsearch k-NN or FAISS?
Elasticsearch k-NN bolted ANN onto a text engine; FAISS is a library that needs extra plumbing. Vector databases bundle scalable indexing, metadata filters, replication, and cloud hosting into one turnkey package.
3. Which vector DB is best for small projects?
For prototypes under ten million vectors, Chroma or pgvector are lightweight and zero-cost to start.
4. Can I store metadata with vectors?
Yes. Most engines attach JSON-like payloads or columns so you can filter on fields (price, tags, dates) and then rank by vector similarity.
5. How big can an index grow before sharding?
Rules of thumb: HNSW in RAM tops out around 1–2 B vectors per cluster; IVF-PQ with disk offload can stretch further but with higher query latency. Plan to shard when latency climbs past your SLA or memory utilisation nears 70 %.
🌟 Follow Us
💬 I hope you like this post! If you have any questions or want me to write an article on a specific topic, feel free to comment below.

